 MENU
MENU 

Researchers investigate language models’ capacity for analogical reasoning in groundbreaking study

Analogy-making is a hallmark of human cognition. Abstract analogical reasoning, our ability to identify structural similarities between different situations, allows us to rely on past experience and previously gained knowledge to navigate the unfamiliar. A University of Michigan team, made up of researchers from CSE and the Department of Psychology, has combined the latest findings in natural language processing with established research in cognitive science to explore language models’ ability to mimic this component of human reasoning and form analogies.
The team’s paper, In-Context Analogical Reasoning with Pre-Trained Language Models, which will appear at the upcoming 2023 Annual Meeting of the Association for Computational Linguistics (ACL), bridges computer science and cognitive psychology, providing new insight into the capabilities of AI technologies as well as revealing the linguistic foundations of human reasoning. The study was authored by recent graduate Xiaoyang (Nick) Hu; CSE PhD student Shane Storks; John R. Anderson Collegiate Professor of Psychology, Linguistics, and Cognitive Science Richard Lewis; and Joyce Chai, professor of computer science and engineering and head of the Situated Language and Embodied Dialogue (SLED) lab.
“Making analogies is a fundamental part of human reasoning that enables us to tackle new situations based on past experience,” said Storks. “It’s an unprecedented time where suddenly we have all these really strong AI systems and language models, so we wanted to understand whether these models demonstrate similar capabilities.”
Imitating analogical reasoning has been a central goal of AI development, but efforts so far have been inefficient and resource intensive, requiring substantial training on specific tasks or hard-coding of knowledge. Past research that has examined the analogy-making capabilities of AI systems has involved pre-training the model on thousands of examples of a single analogy test. Hu, Storks, and coauthors instead focused on testing language models’ inherent capacity for analogical reasoning with no prior exposure to the task.
The team scrutinized language models of various sizes, including GPT-3, a predecessor of OpenAI’s much-talked-about ChatGPT language model. In order to test these models’ analogical abilities, they evaluated their performance on Raven’s Progressive Matrices (RPM), a visual test used to measure abstract reasoning.
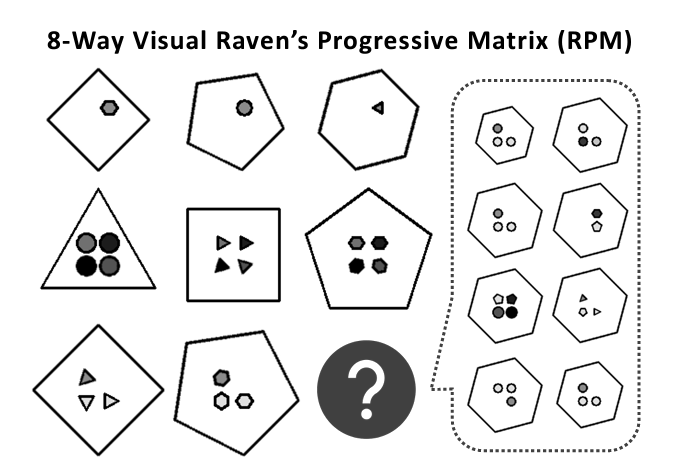
“The Raven’s Progressive Matrices task is the canonical test for analogical reasoning, as well as for general intelligence,” said Hu. “It’s a visual test made up of two to three rows with three items each, with the last item of the last row incomplete. The subject has to infer the rules that govern each row and apply that rule to determine the last item.”
To adapt the test for a language model, the researchers converted the visual components of the task into descriptive terms in language or text form. They took features from the various shapes presented in the RPM task and turned them into numbers and words that could be understood by the language model.
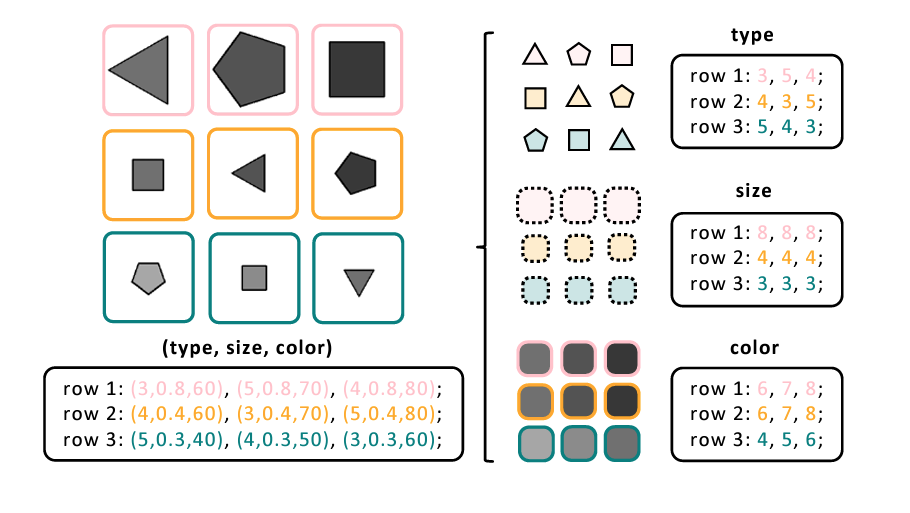
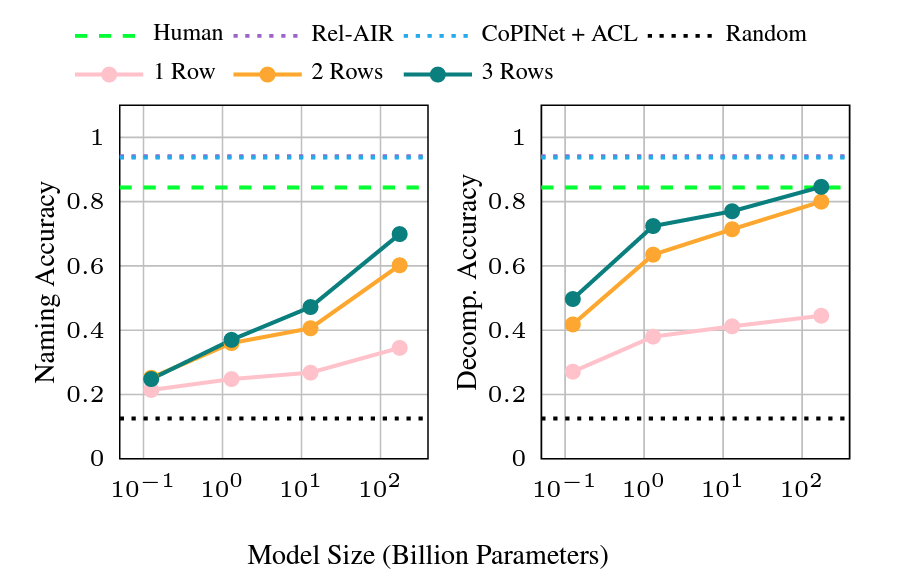
The team’s findings upon running the RPM task in these models were surprising on multiple fronts. First, their tests revealed that the language models performed unexpectedly well on the task without any prior training, even outperforming humans on certain versions of the test.
“The first big surprise is that the model is able to do well on this test at all,” said Hu. “It’s not trained for this test, and the training data is transcribed from a visual data set, meaning the language model wouldn’t have had prior access to it. So this information is essentially new to the model.”
This finding constitutes a significant breakthrough, both in gauging language models’ reasoning capabilities but also in our understanding of human cognition itself.
“These models are trained on natural language from the web, and through this training, they’ve picked up analogy skills that are similar to humans,” said Storks. “There’s a lot of interesting work in cognitive psychology that points out connections between humans’ language capabilities and analogy, so seeing that language models also demonstrate this ability helps us better understand how abstract reasoning works.”
Language models’ strong performance on the RPM abstract reasoning test lends credence to psychological research suggesting that analogy-making goes hand-in-hand with language. Revealing the mechanisms by which language models develop this capacity has powerful implications for our understanding of human learning.
“Language models read text on the internet and then generate language by predicting the most likely next token. Their core function is prediction, and out of this very simple task emerge many interesting abilities,” said Hu. “It’s not inconceivable that humans learn the same way, although LLMs are trained on vastly more textual data than humans.”
According to Storks and Hu, language models’ strong performance on analogical reasoning tasks should in no way contribute to popular concerns about the potential risks of AI. Despite these models’ success on the RPM task, they still have many limitations and cannot substitute human experience and expertise.
“There are many ways in which these language models fall short in comparison to humans,” said Storks. “They are good at this one task, but there is a lot more to human reasoning that is missing in these models.”
While language models cannot exactly replicate human reasoning, their ability to perform certain tasks, such as analogy-making, is an important development. Examining and building on these abilities can enhance AI’s capacity as a tool for human use.
“We hope that language models’ capacity for analogical reasoning can form part of a larger cognitive architecture,” said Storks. “This is a central step in developing intelligent AI systems that can effectively work with and help people.”