 MENU
MENU 

When LLMs and robots meet
An innovative new application of AI technology, researchers at the University of Michigan have invented LLM-Grounder, a 3D visual grounding technique that integrates large language models (LLMs) to equip household robots and AI agents with enhanced grounding ability, helping them better understand and navigate 3D environments.
Imagine getting home one evening, hungry and looking for something to eat. For humans, this is an easy task. We know that hunger means we need food, that food usually lives in the fridge, and how to identify a fridge. For home virtual agents such as Alexa and Siri, on the other hand, this is a tougher request.
While AI agents’ ability to understand natural language text has grown with the advent of LLMs, they lack this level of what is known as grounding, the ability to tie language utterance to objects in the physical world.
“3D visual grounding is one of the building blocks for future robotics tasks,” said Jed Yang, CSE PhD student and first author of the study. “It’s this concept that you can use natural language to find certain objects in a 3D space. This is a very important ability, as many tasks in robotics involve finding a specific thing that the user refers to as the first step.”
Researchers in CSE at U-M, including Yang, master’s student Xuweiyi Chen, PhD student Shengyi Qian, CS undergrad Madhavan Iyengar, Prof. David Fouhey, and Prof. Joyce Chai, took on this challenge by designing an LLM framework for 3D grounding called LLM-Grounder. LLM-Grounder leverages the interactive and intuitive natural language capabilities of LLMs to help grounding tools generate a more accurate layout of 3D spaces, identify objects within those spaces, and better understand objects’ positionality in relation to each other.
“If I want to wash an apple, I need to know where the apple is in the room first. I then need to know where the sink is in the room,” said Yang. “Then, let’s say I want to slice the apple. This is called manipulation, which requires grounding in an even finer grade. I need to know where the edges of the apple are, for instance.”
While today’s AI household tools such as Siri and Alexa may seem pretty futuristic already, these technologies are not designed to perceive the physical world or help people perform tasks in real-world contexts. And although there have been strides in the development of 3D visual grounding tools, these technologies can lack precision.
“There are tools that can locate objects in a 3D space, but they struggle to parse complex requests,” said Yang. “If you ask it to find, say, the chair between the window and the dining table, it would light up all of these items, instead of the individual chair you are looking for.”
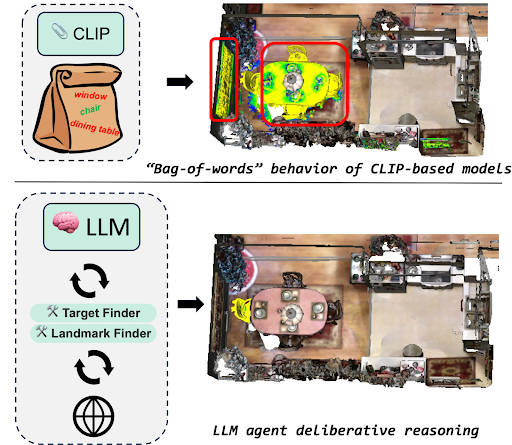
This tendency to identify all the labels in a given prompt is known as the “bag of words” effect, which limits the utility of these tools in locating specific objects. Applying an LLM is a highly effective solution to this problem.
“LLMs are very flexible and good at understanding natural language,” said Yang. “They also have strong general knowledge concerning the size and volume of different objects, and so can better filter out potential false positives.”
In addition to their ability to understand user prompts and identify objects with accuracy, LLMs demonstrate exceptional performance on spatial reasoning tasks, further enhancing their usefulness in navigating 3D spaces.
“If you ask the model to locate the chair between the window and the dining table, it both understands what you’re asking for and can locate the precise object you want by analyzing the XYZ coordinates of the space.”
To use LLM-Grounder, the user first needs a 3D scan of the desired space, a task that can be easily accomplished using the camera on any smartphone, or via a robot exploring and scanning the room. This scan is then run through existing software that will develop a 3D point cloud, or mesh, of the space.
LLM-Grounder adds another layer to these tools, overcoming imprecisions and limitations demonstrated by previous grounding techniques. It thus allows users to essentially interact in a natural way with a 3D scene through an LLM.
In this way, LLM-Grounder, when added to existing grounding techniques, is a versatile and accurate tool that responds intelligently to user requests and functions in virtually any 3D space.
For instance, to return to our first example, if you were to tell LLM-Grounder you were hungry and wanted something to eat, the tool would not only understand what you were asking, but would also be able to reason logically about how to resolve your request and locate the solution within a 3D space accurately.
“In addition to enabling more accurate 3D grounding, LLM-Grounder is designed to be flexible,” said Yang. “It doesn’t require the same rigid language that you see with existing home virtual systems like Google Home or Alexa.”
This combination of an adaptable LLM with prior 3D grounding technologies is a step forward in the development of more intuitive and responsive household virtual agents and robots.
“The latest developments in AI technology and LLMs especially have translated into much stronger language comprehension and grounding capabilities,” said Yang. “Leveraging these abilities, LLM-Grounder enables smooth, natural, and multi-term dialogue with the user, making it more user-friendly and convenient.”
With the development of LLMs accelerating at a rapid pace, this is only the beginning for such applications, and there are certainly further improvements to be made. That said, LLM-Grounder serves as a strong example of the potential for LLMs to transform AI technology.
“This work provides a unique baseline for exciting advancements in the future,” said Chai, “and we are looking forward to seeing where these developments can take us.”